Architecture overview¶
GitHelp is organized around a simple idea: all sources are converted into the same internal document format before retrieval.
The initial use case is MMORE, but the core pipeline is designed to remain project-agnostic. Project-specific behavior is isolated in optional project profiles.
High-level flow¶
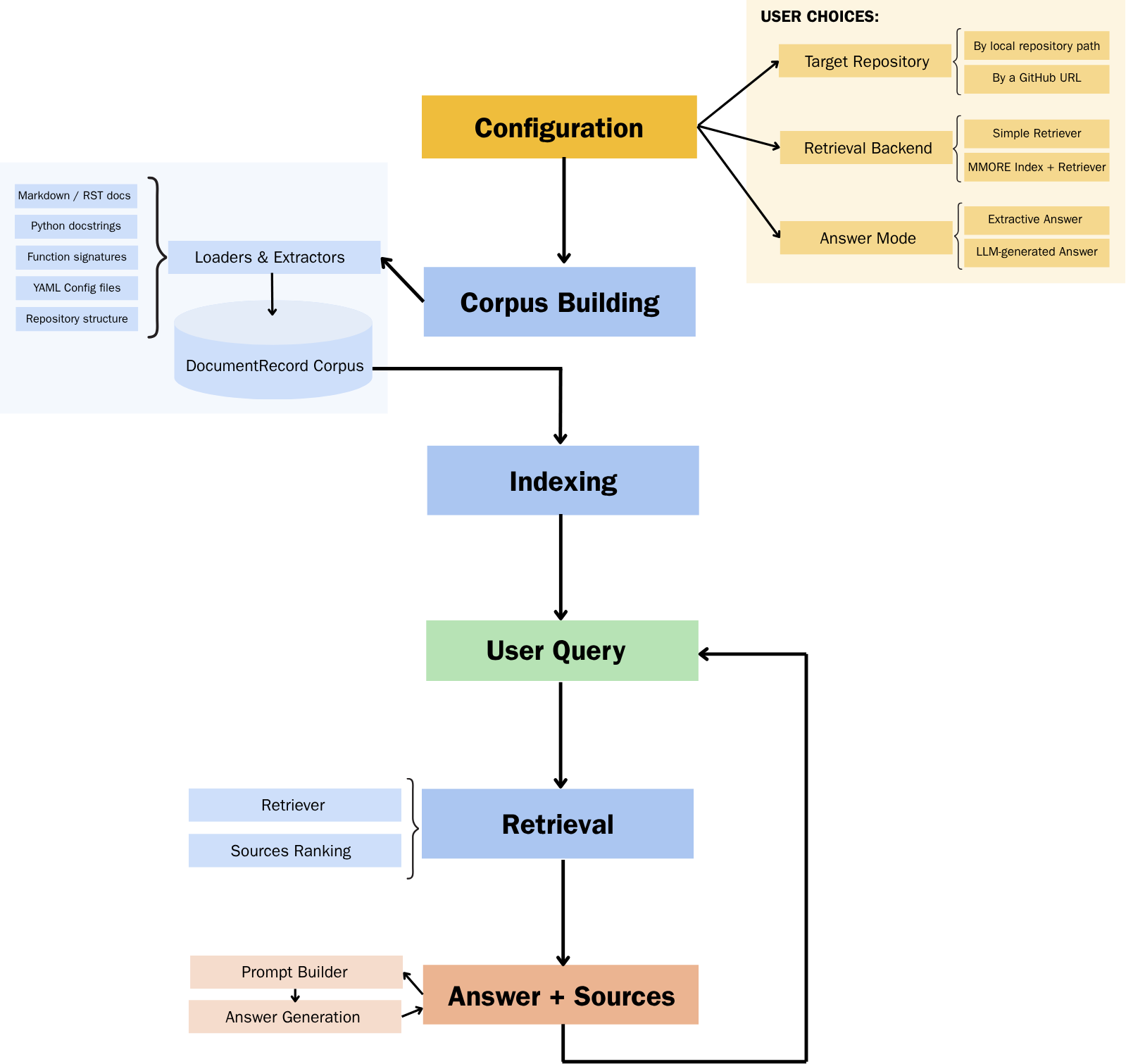
Main design choices¶
GitHelp separates the pipeline into clear blocks:
Block |
Role |
|---|---|
|
Load source files that are already documentation-like. |
|
Extract documentation from source code. |
|
Combine all sources into one corpus. |
|
Export and index the corpus with MMORE. |
|
Retrieve relevant documents. |
|
Hold optional project-specific query expansion, filtering, reranking, and direct answers. |
|
Build prompts and generate answers. |
|
Manage selected projects, generated project configs, and persisted app state. |
|
Streamlit user interface. |
Why keep a GitHelp format?¶
GitHelp uses its own DocumentRecord format instead of exposing MMORE everywhere.
This keeps the project modular:
the corpus can be inspected before indexing;
the simple retriever can run without MMORE;
MMORE can be replaced or updated without rewriting loaders;
retrieved sources keep consistent metadata for citations;
Streamlit can work with project-specific corpora before MMORE indexing is available.
Simple backend vs MMORE backend¶
The simple backend reads a selected corpus.jsonl directly. It is useful for:
local development;
direct checks of newly built project corpora;
debugging retrieval quality;
avoiding MMORE indexing.
The mmore backend is the main MMORE workflow. It retrieves from an MMORE index
when native retrieval succeeds, and it can fall back to the exported
mmore_corpus.jsonl if the local native process fails. That fallback is lexical
and does not use native MMORE/Milvus vector search.
The full MMORE workflow is:
Build corpus → export MMORE corpus → build MMORE index → use backend mmore
For code-, symbol-, and filename-oriented questions, the high-level answering pipeline may merge lexical candidates from the simple retriever with MMORE candidates before applying the project profile.